就业
还是NNT(無い内定、一个和内々定同音的梗)状态,投了十几家,全部都落了。实习过的、老东家的研究所,把我的简历挂了。グループ会社也没给我消息,估计也是挂了吧。之后面了几家大厂全挂1面。
还是先想办法留在这里,就业季时间不等人,先抓紧时间ES。时常感到绝望、加上面试问题比较独特,开卷的人生质问、让我这个小镇做题家本身就没有什么意义的人生,更显得苍白单薄。
活着
深夜负能量、命运的格差、只能说,事已至此,向前看、不要拘泥于过往的细节。
关于论文研究
老板曾在选题的时候,直接把我分配到机械控制和机器人关节制御组,我偏偏想着我就是要实践下具身智能。结果时至今日、才发现做研究一人孤身奋战、不太现实。本科的计算机视觉的研究经验、无法直接无缝迁移。花了大功夫做完模拟,最后倒在了实机的硬件上。心情只能说用痛苦形容。
另外、发现自己做报告和PPT的水平太烂了,自己的研究。却是大纲都没理清楚、甚至水平不如本科时代。
犯下的最大错误
根据兴趣选了一个,实验性质拉满的课题。
研究还是以一个具体的问题、开始研究更好、至少在日本是这样。
老板问到:LLM能用在哪里,感觉不太可靠。本人是想把LLM缝合进机器人任务规划以及错误恢复策略中。类似于各厂的语音助手,既然能有Apple Intelligence,怎么就不能有Robot Intelligence。前者有Agent调用系统API实现任务完成,或者用来操控电脑,后者能否自建动作库,Agent调用动作库来完成实现任务呢。
但是,一套实验弄下来,发现没有核心技术几乎全靠Trick。首先,计算机里的任务基本都可以拆分成固定的API,并且API成功率极高,失败状态较少,现实环境复杂程度远超想象,单是环境识别就足够研究。另动作失败概率也较大。导致最后LLM的作用与其说是规划器不如说是目标与动作提取器。又因为涉及到硬件的东西又极其昂贵,目前做的动作仅有抓取。
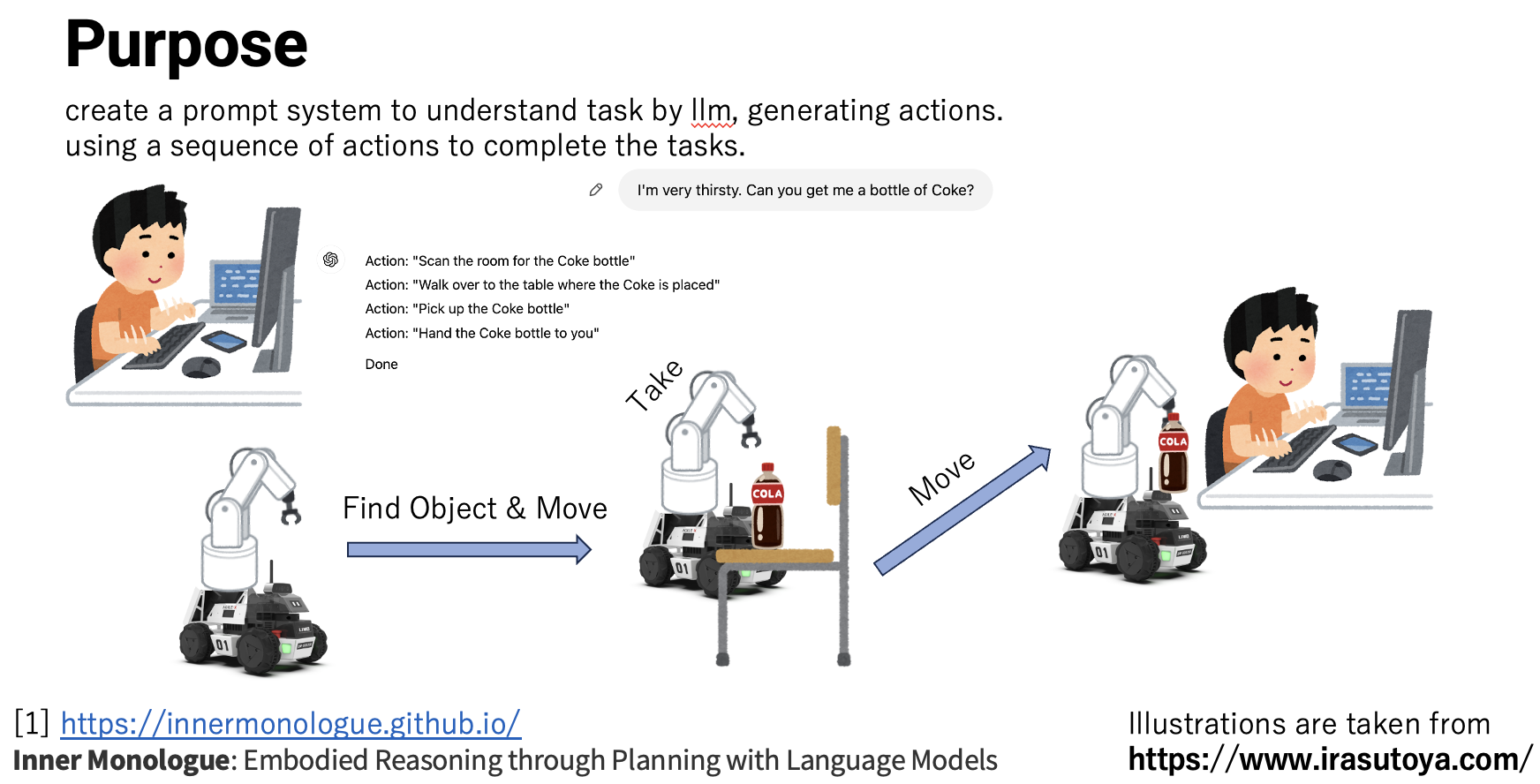
物体抓取

物品调度就不用想了,太复杂了,实机不可能,我放弃了
于是,分割成两个部分
- 设计
Prompt来用LLM分解任务解析为动作API,并考虑如何结合环境多模态。现有论文能reproduce出完整结果的少之又少,很多都是某个模型(比如GPT4)效果还可以,但是换个别的,比如GPT-4o就原地爆炸,明明后者性能更好。 - 运用各种方法,构建动作库,比如传统算法+
slam做导航,GraspNet配合3D点云做抓取,强化学习弄动作姿态等等。只要能work就行。像设计API一样,如果都是不可抢断的任务的话,线性执行的情况只需考虑传入参数和结果就行了。
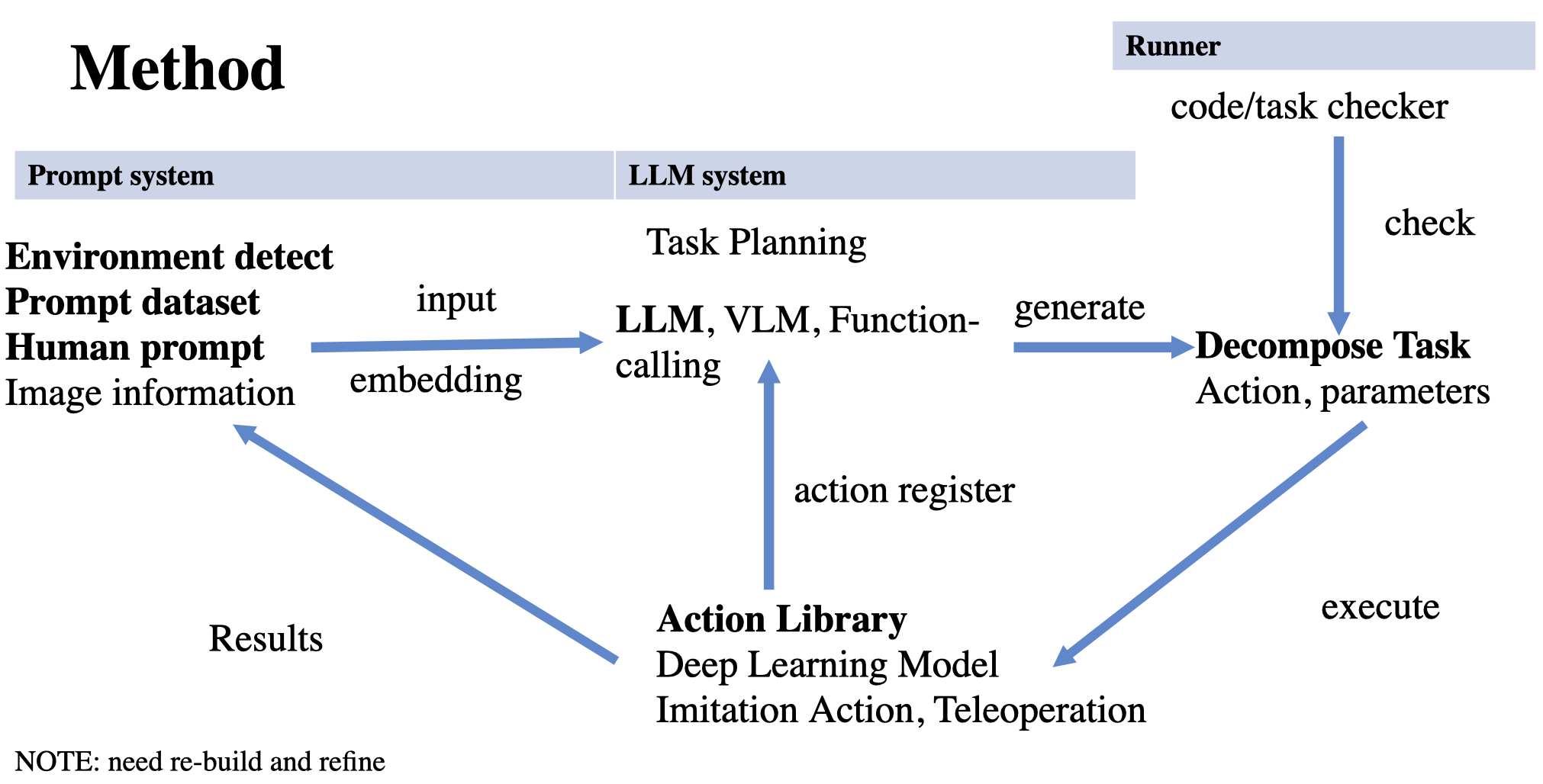
饼学奥义
另外如同大部分人的观点一般,Prompt Engineer就那几套,没必要写成paper,浪费纸张。
OpenAI之前发布会放的,无人机拍照的demo,也是短程任务,因此我觉得我这个自己想的题啊,成功率堪忧,目前仿真的效果就真挺一般的,对于一个普通任务而言,先用LLM做一次大的分解,再用执行器去执行Decomposed Task。
这成功率只能说是感动人心,问题还是硬件最大,其次是模型。尤其是当Reasoning Model出来之后,也许这种分解task的方法,比直接代码生成的方案要好。
现在再看看几篇paper,模拟早就发出来了,而不考虑实机的成功率仅仅40%~60%,而且都是简单的短期任务。
我非常担心,我实机做不出来。光一个Mobile Manipulation就够我想很久了,坐标系标定该怎么弄。
可以说现在目前进展的卡壳、来自于自身能力不足、对自己想的东西,难度估计错误。对LLM估计太乐观、什么多模态,还有太远的路要走。
一个2年的项目、前面半年修完学分、做研究时间就一年半、找工作又是一年、半年能做出什么大文章、mdpi就是我的极限了。